
IJCNC 06
A SMART CLUSTERING BASED APPROACH TO DYNAMIC BANDWIDTH ALLOCATION IN WIRELESS NETWORKS
Mohammed Awad1 and Abdelmunem Abuhasan2
1Department of Computer Systems Engineering, Faculty Engineering and Information Technology, Arab American University Jenin, 240, Palestine
2Department of Planning and Systems Analysis Manager, Arab American University Jenin, 240, Palestine
ABSTRACT
A wireless network consists of a set of wireless nodes forming the network. The bandwidth allocation scheme used in wireless networks should automatically adapt to the network’s environments, where issues such as mobility are highly variable. This paper proposes a method to distribute the bandwidth for wireless network nodes depending on dynamic methodology;this methodology uses intelligent clustering techniques that depend on the student’s distribution at the university campus, rather than the classical allocation methods. We propose a clustering-based approach to solve the dynamic bandwidth allocation problem in wireless networks, enabling wireless nodes to adapt their bandwidth allocation according to the changing number of expected users over time. The proposed solution allows the optimal online bandwidth allocation based on the data extracted from the lectures timetable, and fed to the wireless network control nodes, allowing them to adapt to their environment. The environment data is processed and clustered using the KMeans clustering algorithm to identify potential peak times for every wireless node. The proposed solution feasibility is tested by applying the approach to a case study, at the Arab American University campus wireless network.
KEYWORDS
Clustering Algorithm, Wireless Network, Dynamic Bandwidth Distribution.
1.INTRODUCTION
The growth in wireless telecommunications in recent decades joined mobility offering portable devices and require users today to enter a new stage of operation [1].These networks are born under the concept of autonomy and independence, not requiring the use of infrastructure preexisting or the need to support centralized administration schemes as exist wired networks [2-5]. Of course, there are technical and functional challenges facing these networks, such as routing tasks that depends on some key factors such as mobility and bandwidth. The mobility between two nodes can vary and the limited bandwidth which makes the congestion easy in the wireless network [5]. The optimal distribution and allocation of bandwidth among distributed wireless network nodes has been a hot research topic in the last years [6], [7], [8]; wireless networks are usually followed certain rules and policies to control the maximum allocated bandwidth for each node. The bandwidth allocation process is usually dependent on different factors including traffic type (QoS, best effort) and the number of connected users [9], [10].
Dynamic environments (in terms of users’ mobility) where pervasive communication tools (such as personal mobile devices) are moving and communicating with different access points raise the need for dynamic adaptation in wireless nodes for the requirements of the bandwidth and quality of service. This dynamic and sometimes unpredictable behavior of users imposes challenging tasks on the network control nodes to dynamically adapt and adjust their state especially their bandwidth capacity. Many wireless networks are deployed in environments where it is possible to predict the client’s distribution over time with acceptable probability; in such cases, it is beneficial to build an intelligent control system that enables the network to dynamically adapt its bandwidth allocation strategy over time. In such an approach, the wireless network control system is fed with the extracted data about client’s density at a specific location over a period of time, and then the system adjusts its bandwidth allocation to achieve performance-throughput goals.
The bandwidth allocation algorithms for wireless network nodes applies clustering techniques, based on heuristics divide and conquer [11], which limits the problems management for subsets of nodes and increases network stability [12]. Therefore, the use of clusters has a great impact on overall system performance and proved an efficient form of organization of the bandwidth distribution of the network [13]. Using clustering algorithms to distribute the bandwidth on different nodes of the wireless network will keep the communication limited, prevents redundant traffic between the wireless nodes, stabilize wireless network with a limited overload, to manage the tasks of the cluster members in order to improve the operation of the network. The system can be arranged transmissions for reducing the possibility of data lack or make the cluster members work in low power mode leveraging redundancy in coverage of the area under study and limit the number of collisions by reducing the number of posts exchanged. A lot of bandwidth allocation algorithms based on clusters proposed in the area of sensor networks. All these authors agree that the using of clustering algorithms is fundamental to decide the distribution process of the bandwidth for the whole wireless sensor network.
Clustering is an attractive and smart technique for controlling the users’ distribution over wireless networks, yielding to a better distribution of clients to the available wireless nodes. Clustering algorithms have been intensively used in wireless sensor networks in order to meet application requirements including load balancing and fault tolerance [16]. In [14] the author use k-means clustering algorithm in a network to determine the wireless node with the highest energy to beconsidered as the cluster head, assign the highest energy node to the nearest cluster, so when a node broadcasts its information, all the nodes which are in its receiving range will receive it and again broadcasts it. In this way, the message travels the whole network. The researchers in [15] used K-means clustering algorithm as a common data analysis and mining technique to be developed for a large dynamic network, it used only local communication and synchronization at each iteration; nodes communicate only with their neighboring nodes. Paper [17] analyzes the performance aspects of various centralized clustering techniques for wireless sensor networks. LEACH-Centralized, K-Means-CP, FCM-CP and HSA-CP protocols have been compared with respect to clustering and data delivery process for various realistic topologies.In [18],the author proposed two new clustering algorithms based on Fuzzy C-Means algorithm; the cluster head is selected initially based on the nearest to the center of the cluster, and the node having the higher residual energy selected itself as a cluster head.In [19], the author proposed a hybrid anomaly detection technique with the application of k-means clustering. The data set is clustered using weka 3.6.10. After clustering, we get the threshold values of various network performance parameters (traffic and delay), which used to detect the anomaly.In [20], a new dynamic reclustering LEACH-Basedprotocol reduced the energy consumption and extending the network’s lifetime depends on balance energy consumption of cluster heads by generating clusters with the almost equal number of during each round of the network lifetime. Our approach in clustering will be based on K-means clustering algorithm that leverages an unsupervised learning
methodology to group client devices into wireless nodes. In this paper, we propose a novel cluster-based bandwidth allocation scheme for wireless networks, where a wireless node is made capable of adapting its bandwidth allocation over a period making use of the clustering process that determines the potential number of clients in its domain. Our case study is the campus of the Arab American University of Jenin.
2.THE PROPOSED METHODOLOGY
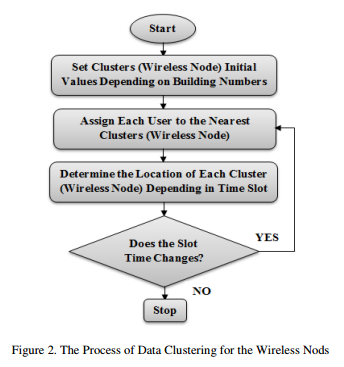
The basic idea behind our dynamic bandwidth distribution model is to build a distribution strategy in which each wireless node adapts to the dynamic bandwidth requirements of its potential users; to be able to adapt, the wireless node must be fed by statistical data about the expected number of users at every time slot; which is assumed possible to be predicted and fed to the node in advance.Figure 1 depicts the proposed architecture of the dynamic bandwidth allocation strategy to a wireless network, the details of each step is explained as following:

Data Extraction: is the process of retrieving the wireless network customer’s raw data out of possible data sources (e.g. students’ registration records).
Data Processing: is the process of applying the necessary processing and transformation steps on the data to convert it into statistical information about the distribution of clients in terms of time slots, this information will be used to determine the expected load of each wireless node in the network.
Data Clustering: is the process of performing a statistical data analysis on the processed clients distribution, the goal of this step is to group clients into clusters and assign them the required resources (in terms of wireless nodes and bandwidth) to achieve the best quality of service. We use K Means clustering algorithm to build the possible clusters as illustrated in figure 2.
Data feeding to the control system: in this step, the clusters that are built in the data clustering process are fed to the wireless network control system to enable it to assign the required bandwidth to each wireless node.

We applied our proposed dynamic bandwidth allocation strategy on the wireless network deployed in the Arab American University of Jenin (AAUJ) campus, the campus is composed of eight main buildings where the clients (students) are usually grouped or centered as shown in figure 2.
The AAUJ’s courses timetable is divided into two categories:
- Saturday, Monday and Wednesday (S, M, W) classes, where each class is 50 minutes starting at 8:00 AM up to 4 PM, with a break between classes for 10 minutes.
- Sunday and Tuesday (N, T) classes, where each class is 80 minutes starting at 8:00 AM up to 4 PM, with a break between classes for 10 minutes.
The proposed scheme is to dynamically allocate bandwidth to wireless nodes depending on the number of users located at each building in a given period of time; which can be extracted by performing statistical analysis on the student registration records. The idea is to extract the students’ distribution on buildings at a given time period within the day and feed it to the wireless control nodes to adjust the bandwidth allocation in a manner that satisfies the nodes expected load.
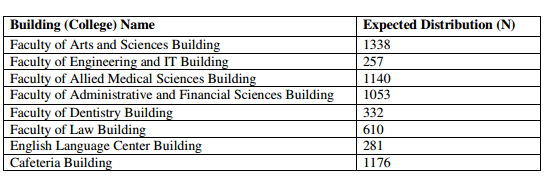
The data extraction and processing processes will incorporate the following steps for each building and time slot in the university campus:
- Extract the number of students enrolled in classes at the specified time slot and building, denote as N1.
- Extract the number of college students who are not enrolled in current time slot classes but they are enrolled in later time slots’ classes in the specified building, denote as N2
- Extract the number of students who are enrolled in specializations offered by each college, denote as N3.
- Calculate the number of students who are expected to exists on the building at a specified time slots (denote as N), using this formula:

The following assumptions are made regarding the process of data processing:
1. The expected students in a specific building at a specified time slot are :
- Students who are enrolled in classes at that building at that time slot.
- Half of free college students who are enrolled in classes that start after the current time slot.
- 30% of free university students who are enrolled in classes that start after the current time slot are expected to be at the cafeteria building.
2. 20% of free university students who are enrolled in classes that start after the current time slot are randomly distributed on the university campus.

3. 30% of free university students who are enrolled in classes that start after the current time slot are assumed to be grouped in the Cafeteria building.
Table 1.Shows sample statistical information about each building in the campus at the time slot Saturday 08:00 Am.

The next step is to apply a clustering algorithm (typically K-Means) to identify the possible groupings of students over the campus buildings. In a wireless sensor network whose nodes are randomly distributed in a field hundreds of meters across is useful to divide the set of nodes into subsets having smaller geographic proximity, so that transmission distances reduce and contribute to energy saving. This technique of dividing the set of nodes into smaller subsets depending on the number of users is called clustering and has been widely studied [16]. The information reaches the clusters (wireless nodes), depending on the number of users which depends on the lectures schedule of each building at the campus. The dynamic control system for allocation the bandwidth for each building depends on the number of users in this building, which means the allocation process of the bandwidth changes in each instance of time.
K-Means clustering algorithm is based mainly on the Euclidian distances, it creates clusters depending on four steps. K-means position starts when k centroids evenly distributed in the network, then assign nodes to each centroid according to the minimum distance between the node and the centroid. The new position centroid is determined by the average xiandxj of the nodes belonging to the centroid. If the centroid position changes K-means runs again, otherwise the algorithm ends.K-Means Clustering, with k number of wireless nods used in the initialization, assign each input data point (user) to the nearest clusters depends on Euclidean distance the process performed by the following pseudocode:


The values of these wireless nodes K(Ci1, Ci2, …, Cik), where Cik is the value of the k th wireless nodes of the i th users. As other clustering algorithms, k-means clustering requires to calculate the Euclidean distance D as shown in the following expression:

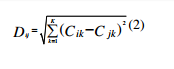
Where Cik, Cjk is the value of the k thwireless nodes of the i th or jth users. Each data point (user) is placed in the cluster associated with the nearest starting point. New cluster centroids are calculated after all period of time depends on the lectures timetable, which assign the datapoints (users) to a cluster. Suppose that Cik represents the centroid of the kth wireless nodes of the i th users, the process calculated depends on the following expression:

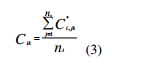
where C * i,jk is the k th wireless nodes of the jth users assigned to the ith user in each cluster and where ni is the number of data points in cluster i.
3.EXPERIMENTAL RESULTS
We applied the proposed methodology on the wireless network of the Arab American University campus, for the wireless sensors distributed in the university campus, we assume to use one wireless node in each building, the four main processes of the methodology have been implemented,Figure 4 shows the expected Load for one of the buildings, it is clear that the load in high in the morning period, stable in the midday period and low in the end of the university day. From Figure 4, it’s clear that the smart allocation of the wireless bandwidth on the building will be a helpful process to make the connection of each student more stable and fast.

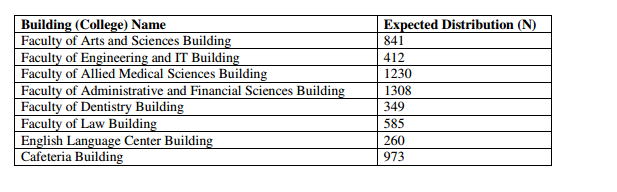
To illustrates the performance distribution of the proposed methodology on the university building at each time slot, we select time slots for the day beginning, midday and at the end of the university day depending into two categoriesof the courses timetable ([Sat., Mon., and Wed], [Sun and Tue]), figures 5 and 6 show a sample distribution of students at time slot 08:00-08:50 (S,M,W) and 08:00- 09:30(N,T) AM respectively.
Table 2. Shows sample statistical information about each building in the campus at the time slot SMW 08:00 Am.


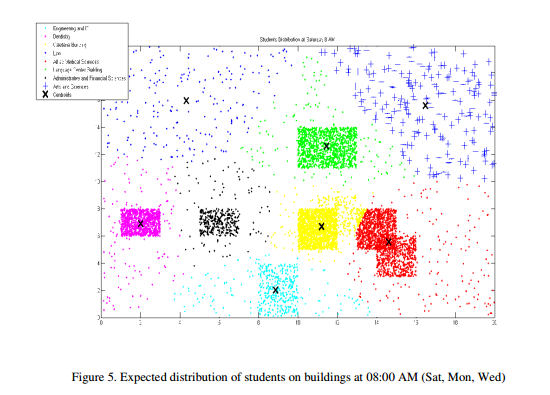
From Figures 5 and 6, it’s clear that the density of users in this time slot, some buildings have big number of users, this lead the system to increase the bandwidth allocation for these buildings. (eg. The bandwidth allocation to cafeteria building will decrease; whereas the bandwidth allocation for the Faculty of Allied Medical Sciences Building will increase to cover the increased number of users)
Table 3. Shows sample statistical information about each building in the campus at the time slot NT 08:00


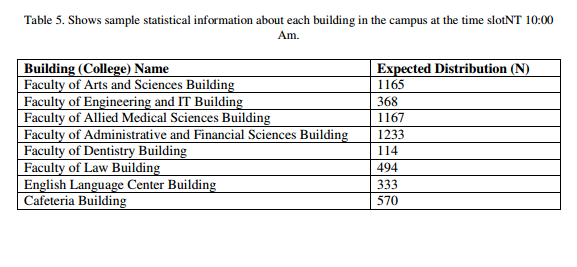
Table 4. Shows sample statistical information about each building in the campus at the time slot SMW 10:00 Am.


Figures 7 and 8 show a sample distribution of students at time slot 10:00-10:50 (S, M, W) and 11:00- 12:30 (N, T) AM. Which are the most occupied times slot at the university campus, because it is the time preferable for the students and lecturers.
Figures 7 and 8 illustrated the distribution of users in this time slot,it is clear the density of users in this time slot in the majority of buildings, which leads the system to approximately normal bandwidth allocation for all the buildings. The majority of the cluster in these figures, especially the clusters of the buildings which havedensity users in this time slot, but the clusters appear outside of these main buildings in the university campus need small bandwidth allocation.




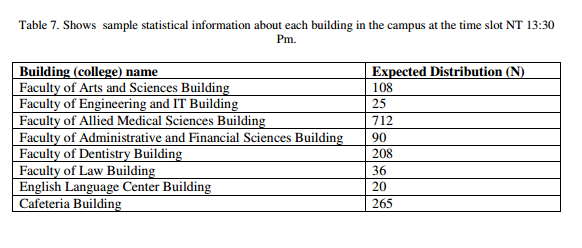

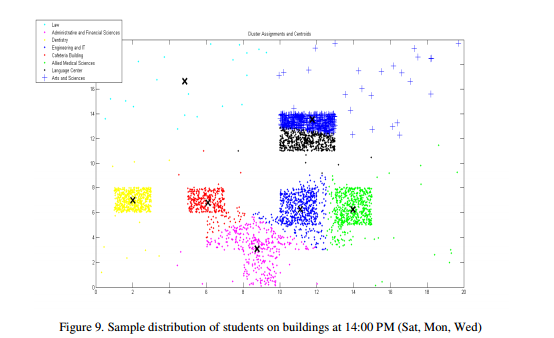

Figures9 and 10 show a sample distribution of students at time slot 14:00-14:50 (Sat, Mon, Wed) and 14:00- 15:30 (Sun, Tue)PM. From Figures 9 and 10, it’s clear that a small number of users in this time slot are expected to exist, all buildings have small number of users, this lead the system to decrease the bandwidth allocation for these buildings and might redirect bandwidth resources to another sources. From the empirical results that were conducted on the AAUJ campus wireless network, we conclude that the proposed technique of dynamic distribution and allocation of bandwidth using KMeans clustering produces a smart bandwidth allocation strategy that guarantees the network QoS in terms of efficiency and bandwidth allocation, which leads to the possibility to further extend this technique to be employed in larger wireless network where it is possible to predict users density over time.
4.CONCLUSION
Clustering is an important technique which use to organize the position and capacity of wireless nodes. Nowadays the continuous connectivity of users to wireless sensor network is very important. The stable connectivity depends on the nearest position of the wireless node to the user.In this paper, we proposed a smart and dynamic bandwidth allocation technique for wireless networks, leveraging KMeans clustring algorithm to extract the potential load for each wireless node in a predefined time period. This technique is implemented using the statistical data of the potential users domain; in the case study provided in this paper, we employed the students timetable to extract the potential distribution of users on the campus buildings, by applying KMeans clustering we were able to specify potential peak times for each wireless node of the university campus wireless network, and thus enabling the wireless network to adapt its bandwidth requirements according to the expected loads. The experimental results shows in a clear way the variance in the expected load for each wireless node (or a building), thus making it possible to control the number of wireless nodes required to be installed in each building in addition to their characteristics. We think our results makes this smart distribution method feasible to be implemented in a larger scale wireless network where it is possible to predict the expected load for each potential wireless node(s).
REFRENCES
[1] Corson. S, Macker. J.(1999), Mobile Ad Hoc Networking (MANET): Routing Protocol Performance Issues and Evaluation Considerations. New York, NY, USA: ACM.
[2] Chong. C-Y, Kumar. SP, (2003), “Sensor Networks: Evolution, Opportunities, and Challenges”, Proceedings of the IEEE, Vol. 91, No. 8, pp. 1247-1256.
[3] Heinzelman, W. B., Chandrakasan, A. P., & Balakrishnan, H. (2002). Application-specific protocol architecture for wireless microsensor networks”. IEEE Transactions on Wireless Communications, Vol. 1, No. 4, pp. 660-670. [4] Akyildiz, I. F., Su, W., Sankarasubramaniam, Y., & Cayirci, E. (2002). “Wireless sensor networks: a survey”. Computer networks, Vol. 38 No. 4, pp.393-422.
[5] Samaras, I. K., Hassapis, G. D., & Gialelis, J. V. (2013). “A modified DPWS protocol stack for 6LoWPAN-based wireless sensor networks”. IEEE Transactions on Industrial Informatics, Vol. 9 No. 1, pp. 209-217.
[6] Visoottiviseth, V., Trunganont, A., & Siwamogsatham, S. (2010). “Adaptive bandwidth allocation for per-station fairness on wireless access router”. International Symposium on Communications and Information Technologies (ISCIT), IEEE, pp. 238-243.
[7] Pan, R., Prabhakar, B., Bonomi, F., & Olsen, B. (2008). “Approximate fair bandwidth allocation: A method for simple and flexible traffic management”. 46th Annual Allerton Conference on Communication, Control, and Computing, IEEE, pp. 1081-1085.
[8] Angelini, D., & Zorzi, M. (2002). “On the throughput and fairness performance of heterogeneous downlink packet traffic in a locally centralized CDMA/TDD system”. In Vehicular Technology Conference, 2002. Proceedings. VTC 2002-Fall. 2002 IEEE 56th , Vol. 1, pp. 510-514.
[9] Jiang, Z., & Shankaranarayana, N. K. (2001). “Channel quality dependent scheduling for flexible wireless resource management”. In Global Telecommunications Conference, 2001. GLOBECOM’01. IEEE.Vol. 6, pp. 3633-3638..
[10] Bianchi, G., & Campbell, A. T. (2000). “A programmable MAC framework for utility-based adaptive quality of service support”.IEEE Journal on Selected Areas in Communications, Vol. 18, No. 2, pp. 244-255.
[11] Ahmad, A., Paul, A., Rathore, M. M. (2016). “An efficient divide-and-conquer approach for big data analytics in machine-to-machine communication”. Neurocomputing, Vol. 174, pp. 439-453.
[12] Israr, N. and I. Awan, (2007). “Multihop clustering algorithm for load balancing in wireless sensor networks”, International Journal of Simulation, Systems, Science and Technology, Vol. 8 No. 1, pp 13 – 25.
[13] Younis, O., Krunz, M., & Ramasubramanian, S. (2006). “Node clustering in wireless sensor networks: recent developments and deployment challenges” 25.
[14] Sasikumar, P., & Khara, S. (2012). “K international conference on Computational intelligence and communi pp. 140-144.
[15] Datta, S., Giannella, C., & Kargupta Network”. In Proceedings of the SIAM Data Mining Conference
[16] Navjot K. J, Sandeep S. W, (2014)“A R WSN”, International Journal of Advances in Computer Networks and Its Security 3.
[17] Raval, G., Bhavsar, M. Patel, N. (2015). “Analyzing the Performance of Centralized Clustering Techniques for Realistic Wireless Sensor Network Topologies” pp. 1026-1035.
[18] Souiki, S., Hadjila, M., & Feham, M. (2015). “Fuzzy based clustering and energy efficient routing for underwater wireless sensor networks”. Inte Communications, Vol. 7, No.2,
[19] Wazid. M, (2014) “Hybrid Anomaly Detection using K Networks”,Center for Security, Theory and Algorithmic Research, International Information Technology, IACR Cryptology ePrint Archive: 712, pp. 1
[20] Ijjeh, A., Ijjeh, A., Al-Issa, H., Thuneibat, S. (2015). “dynamic re protocol for wireless sensor networks”,International Journal of Communications (IJCNC) Vol.7, No.6, pp.99-110
Authors
Mohammed Awad received the Ph.D. degrees in Computer Engineering from the Granada University Spain. From 2005 to 2006, he was a contract Researcher at Granada University. Since Feb. 2006, he has been an Assistant Professor in Computer Engineering Department, College of Engineering and Information Technology at Arab American University . At 2010 he has been an associate Professor in Computer Engineering. He worked for more t han 10 years at the Arab American University in academic Position, in parallel with v arious Academic administrative positions. (Departments Chairman and Dean Assistant, and Dean of Scientific Research/Editor-In-Chief, Journal of AAUJ). Through the research and educational experience, he has developed strong research record. His research interests include: Artificial Intelligence, Neural Networks, Function Approximation of Complex Systems, Clustering Algorithms, Input Variable Selection, Fuzzy Expert Systems and Genetic Algorithms.
. At 2010 he has been an associate Professor in Computer Engineering. He worked for more t han 10 years at the Arab American University in academic Position, in parallel with v arious Academic administrative positions. (Departments Chairman and Dean Assistant, and Dean of Scientific Research/Editor-In-Chief, Journal of AAUJ). Through the research and educational experience, he has developed strong research record. His research interests include: Artificial Intelligence, Neural Networks, Function Approximation of Complex Systems, Clustering Algorithms, Input Variable Selection, Fuzzy Expert Systems and Genetic Algorithms.
Abdelmunem Abuhasan is a Master student at the Arab American University with particular interests in computer security, web security, data mining and software engineering. He is working since ten years as the manager of software development department at the Arab American University. He holds a B.A. in Computer Science from the Arab American University.

