WHITE SPACE STEGANOGRAPHY ON TEXTBY USING LZW-HUFFMAN DOUBLECOMPRESSION
Gelar Budiman and Ledya Novamizanti
Electrical Engineering Faculty, Telkom University, Bandung, Indonesia
ABSTRACT
Privacy, especially in a cellphone, is an important thing and should be protected. Steganography is a method used to protect a sensitive information. The issue tried to be discussed in this study is the issue on inserting technique in a text through a simple method of White Space Steganography on android. The inserted message has been compressed through a double compression method by using LZW and Huffman so that the size of message to be inserted can be minimized while the capacity of the inserted message can be minimized. The compression shows that the compression ratio much depends on the type of text input to the text to be sent; the more the repetition or duplication found on the message, the smaller the compression ratio will be. The compression process using Android based smartphone is relatively fast with the average duration of 0.045 seconds, either for the insertion or extraction.
KEYWORDS
White Space Steganography, teks, android, compression, LZW, Huffman Coding
1.INTRODUCTION
Difficulties in protecting one’s privacy is getting challenging along with the development indigital communication technology. One of the popular communication technologies tha tconsistently develops is cellphone, particularly android. Cellphone is often used as a medium tosave and send sensitive information. As cell phone is an accessible device, the protection towardssensitive information within the cellphone becomes essential.One of the methods that can be taken as to protect the information is by using steganography, i.e.a technique to hide information by inserting a message into another message[4], so that it is onlythe intended person who will aware about the message. One of the recent studies onsteganography is the one conducted by Ratna E. and V.K. Govindan, i.e. the unlimited payloadsteganography[4]. However, the study on LZW and Huffman compression has also beenconducted, as that one of Linawati and Henry P. Panggabean[6]. Compression is usually conductedon the watermarking technique towards cover image after the inserting process is taken, asconducted by Dr. Ajit Singh and Meenakshi Gahlawat[9]. Meanwhile, all of the studies have notbeen implemented on android.In this study, double compression will be conducted by using LZW-Huffman technique on textualdata which is then hidden through white space steganography. The system will then beimplemented on android. By using LZW and Huffman techniques on the compression process, itis hoped that the capacity of the hidden textual data can be bigger than the previous study.
2. THEORETICAL BACKGROUND
2.1 White Space Steganography
Steganography is derived from Greek–Steganós which means hide and Graptos which meanswriting – that in general it can be defined as hidden writing[7]. In general, steganography is an artand knowledge in hiding a message into a medium in a way that it is only the sender and thereceiver who know or realize that there is actually a secret message[10].Steganography in digital era has been much developed. The media that can be used forsteganography are text, picture, audio, and video. One of the simple media that can be used issteganography on texts through White Space Steganography method. White Space Steganographyis a simple steganography method by using “space” and “tab” characters as to show hiddenmessage bits. “Space” and “tab” can be used since it is difficult to recognize and is not reflected in text viewer.
2.2 LZW Compression Method
The storage of big size data or files takes up a big storage capacity. Pertaining to this,compression technique can be used to minimize the data size. Compression is a process inencrypting a group of data into a code as to optimize the storage space, as well as the transmissiontime[3].Lossless compression method is data compression method which can generate data identical tothe original one, i.e. by reconstructing the compressed data[1]. One of the examples of loss less compression is by using LZW algorithm.LZW (Lempel Zev Welch) algorithm is developed by using compression method developed by Ziv and Lempel in 1977. This algorithm carries out the lossless compression by using dictionary,where the text fragments are replaced by the index derived from a “dictionary”. Character Stringis replaced by table code created for each string coming. Table is made for the input reference forthe upcoming string[4].The whole LZW compression algorithm is as follow:
1) Dictionary is initialized by all basic existing characters : {‘A’..’Z’,’a’..’z’,’0’..’9’}.
2) P the first character in character stream.
3) C the upcoming character in characterstream.
4) Isstring(P + C) found in dictionary ?
• If yes, soP P + C (combine P and C into a new string).
• If not, so :
i. Output a code to replace string P.
ii. Add string (P + C) into dictionary and give the next number/code that has not been
used indictionary to the string.
iii. P C.
5) Is there still any upcoming character remained in character stream
• If yes, return to step 2.
• If not,output the code that will replace string P, and terminate the process (stop).
The decompression process in LZW is conducted through the principles similar to those incompression process. In the beginning dictionary is initialized by all existing basic characters. Ineach step, the code is then read one by one from code stream and taken from string in dictionarywhich corresponds to the code. A new string is then added into dictionary. The following is thefull decompression process:
1) Dictionary is initialized by all the existing characters : {‘A’..’Z’,’a’..’z’,’0’..’9’}.
2) CW the first code stream (referring to one of the basic characters).
3) Consult dictionary and output string of the code (string.CW) into character stream.
4) PW CW; CW the upcoming code ofcode stream.
5) Is string.CW found in dictionary ?
• If yes, then :
i. output string.CW to character stream
ii. P string.PW
iii. C the first character of string. CW
iv. Add string (P+C) into dictionary
• If not, then :
i. P string.PW
ii. C the first character of string.PW
iii. output string(P+C) into character stream and add the string into dictionary(it finally
can correspond with CW);
6) Is there any other code in code stream?
• If yes, back to the step 4.
• If no, terminate the process (stop).
2.1 Huffman Compression Method
Huffman coding is a popular method for data compression. It serves as the basis for severalpopular programs run on various platforms. Some programs use just the Huffman method, while others use it as one step in a multistep compression process. The Huffman method generallyproduces better codes when the probabilities of the symbols are negative powers of 2. Huffmanconstructs a code tree from the bottom up (builds the codes from right to left). Since itsdevelopment, in 1952, by D. Huffman, this method has been the subject of intensive research intodata compression.The algorithm starts by building a list of all the alphabet symbols in descending order of theirprobabilities. It then constructs a tree, with a symbol at every leaf, from the bottom up. This isdone in steps, where at each step the two symbols with smallest probabilities are selected, addedto the top of the partial tree, deleted from the list, and replaced with an auxiliary symbolrepresenting the two original symbols. When the list is reduced to just one auxiliary symbol(representing the entire alphabet), the tree is complete. The tree is then traversed to determine thecodes of the symbols.
3.SYSTEM DESIGN
3.1 Analysis and Design
Problem to be studied is the insertion technique on text by using a simple method of White SpaceSteganography. The message inserted has been compressed by using a double compressionmethod of LZW and Huffman so that the size of the message is smaller and the capacity of theinserted message is bigger.
 Figure 2 General Model of the System
Figure 2 General Model of the System

3.2 System Flow Chart
 Figure 3 Flow Chart of the Compression-Embedding and Decompression-Extraction Process
Figure 3 Flow Chart of the Compression-Embedding and Decompression-Extraction Process

The message input is a text used as the secret message that will be inserted into white spacesteganography. The text input should be in the list of LZW dictionary, if not, there will be awarning to reinput the text. The input text will then be compressed by using LZW (Lempel ZevWelch) technique. LZW technique uses dictionary as its reference. LZWpriorinitial dictionaryconsists of 66 initial dictionaries comprising the characters usually used, which can be developedinto 128dictionaries. The 128 dictionaries are used to get a maximum result in the upcomingHuffman compresion. Table 1intheappendix shows the prior initials of the LZW dictionary.LZW compression results in the numbers representing dictionary index used. LZW dictionary hasa range of 0 and 127where each numbers requires the number of bits as to represent it. Thenumbers have been compressed by using Huffman algorithm with a static Huffman tree tablewhich has been determined previously. Static tree table is used if it is difficult for the receivers toredecompress the steganography message by using adaptive tree table as they do not have the adaptive tree table. Table2 in appendix shows theexample of Huffman tree table used withdifferent probability of occurrence of LZW dictionary index.The Huffman compression results in representation bits. These bits will be inserted into the covertext by altering bit ‘1’ into ‘Tab’ and ‘0’ into ‘space’. By using Tab and space characters, themessage can be difficult to be recognized. The message output comprises the text cover alongwith the result fromwhite space steganography. The text output will be reproceeded as to obtain the secret message inserted previously. The text cover and the inserted message using ‘tab’ and‘space’ included in the message generated from steganography will be separated first.The white space steganography extraction process is quite simple, i.e. by changing the ‘Tab’character into bit ‘1’ and ‘Space’ character into bit ‘0’. Huffman decompression is same with theone used in the compression by using static Huffman tree table which has been determinedpreviously. Since it uses static Huffman tree table, the receiver is not required to ask the huffmantable to the sender since the static tree table is included in the program. LZW decompressionprocess is conducted by adapting the adaptive dictionary so that the inserted secret message can be generated.
4. APPLICATION PERFORMANCE ANALYSIS
The test in the study is aimed at:
1. Finding out the sytem perfomance in the form of compression ratio
2. Finding out the system performance in accordance with the compression anddecompression time.
3. Finding out and analyzing the system performance towards different inputs
4.1 Test Setting
The test is taken to be set on android smartphone Samsung S Advance device, with the followingspecification :
1) Processor Dual Core 800 MHz.
2) Internal Memory: 4 GB Storage.
3) RAM 768 MB
4) External Memory: 16 GB
5) OS Android 2.3 Gingerbread.
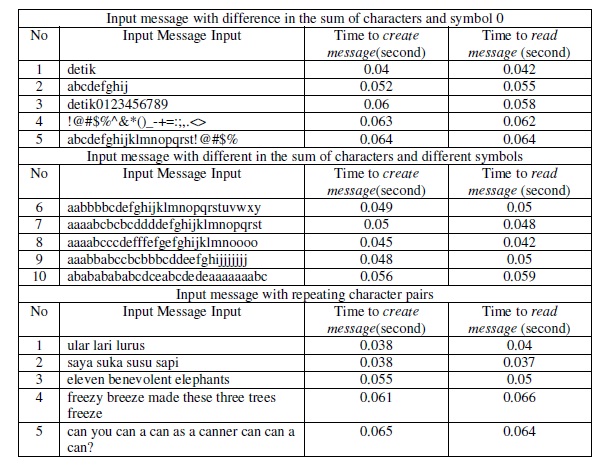
6) PLS TFT capacitive touchscreen, 16M colors (480 x 800 pixels, 3.8 inches (~246 ppipixel density))Message input to be inserted are comprised by different input samples as can be seen in table 3 inappendix. The scenario used in the test is as follow:
1. Testing the compression calculation by using the manual calculation and comparing it byusing the program made.
2. Measuring the compression ratio of the message input with different sum of charactersand symbols.
3. Measuring the time used in the compression and decompression
International Journal of Computer Networks & CommunicationsParameters used in the application test are compression time and compression ratio. The processtime is an important factor in compresion and decompression process. Ratio in percentage iscalculated using the following equation


4.2 Test Result
4.2.1 Test on the Compression Ratio Manual Calculation and the Calculation using Program
The following is the explanation on the compression result obtained from the manual calculation compared with the calculation using program. Meanwhile, the LZW compression process withthat input can be seen in table 4 in appendix.The dictionary index generated from LZW compression will be compressed by using Huffman compression with static tree table.

The test result on the program showing the application interface can be seen in figure 4
 Figure 4 The application interface on the test of input
compression and the decompression result
Figure 4 The application interface on the test of input
compression and the decompression result
It can be seen that the LZW compression ratio is 18.18% and theIt means that the result generated from the program is same withthat one resulted from the manual calculation.
4.2.2 Compression Ratio
The test is taken with ratio of the number character with input message symbol number 0. Table 5in appendix shows compression ratio as the test result on several processes conducted in theimplemented system. Table 5 can be presented in the analysis graphic as can be seen in figure 5.


The test above shows that the number of characters and symbol is equal that causes no repeatingcharacter pair defined that causes LZW compression ratio of 1:1. The scenario above shows thatit is only Huffman compressionthatworks,where the compression ratio will increase if the inputmessage character has a small bit representation in staticHuffman tree table. A non letter symbolhas a big bit representation so that the ratio is small.The following test is the test on the differenceof the input message of 30 characters that hasdifferent total number of symbols. The test can be seen in table 6 in appendix. Table 6 can besummarized into the graphs in Figure 6.


From the test, it can be seen that with the same total number of characters, the bigger difference inthe sum of character and the sum of symbol, the bigger LZW+ Huffman will be. It is because that big difference means that there are many repeating symbols and as a consequence, LZWcompression is getting better. Unfortunately,Huffman compression ratio is getting smaller if thereare many repeating high bit symbols. However, LZW compression value will exceed the Huffman
compression if the repeating symbols are found more, which also means that even if thedifference is getting bigger, the Huffman+LZWdouble compresion ratio is still better.The following test is the test using input message with repeating character pair. The test processcan be seen in table 7 in the appendix. From the table, it can be concluded in the graphs in figure7


The test shows that the Huffman+LZW double compression ratio is getting bigger if the numberof input characters as well as the number of repeating character pairsare also getting bigger. It isinfluenced by the LZW compression which is getting better if the number of repeating charactersis increasing. Meanwhile, for Huffman, the size of compression depends on the number of bitgiven for each character.
4.2.3 Process Time
Table 8 in the appendix is the result of process time used as to create and read messages involving20 samples. However, figure 8 shows the visualization in accordance with table8


The process time used is almost same for all the tests conducted since all of the tests have asimilar process. However, the input message with more characters requires a longer time. Theprocess time cannot be separated from thehardware used in the experiment.
5. CONCLUSION AND RECOMMENDATION
5.1 Conclusion
Based on the implementation of steganography of text using double compression with LZWHuffman,it can be concluded that:
1. From the compression ratio obtained, it can be seen that the system is able to produce different ratio depending on the input used. If the message input consisting of several repeating character pairs, the compression ratio will be big. If the input message involves fewrepeating words, the compression ratio will be smaller due to the LZW compressionalgorithm. If the input message is only comprised by symbol, instead of letter, thecompression ratio will be small since in the static huffman tree table, the bit for non lettercharacter is represented to be big and the compression ratio will be big if the input messagecomprises many letter characters.
2. The speed in the process time as to generate text stego is relatively fast and the influence ofthe input that has many repeating words as well as the one that has few repeating words isInternational Journal of Computer Networks & Communications (IJCNC) Vol.7, No.2, March 2015132not much different. The process time tocreate messageandto read messageis not muchdifferent.
5.2 Recommendation
1. Instead of text, picture or sound can also be usedas the media in steganography, i.e. as toensure a higher security level.
2. Other compression algorithm can also be used as to get a proper compression ratio.
REFFERENCE
[1] Deorowicz, Sebastian.20013. Universal Lossless Data Compression Algorithms. Gliwice:SilesianUniversity of Technology
[2] D. Salomon. Data Compression: The Complete Reference. Springer, 1998.
[3] Howe, D. Free Online Dictionary of Computing, http://www.foldoc.org/
[4] Kanikar, Prashasti, Ratnesh N. Chaturvedi dan Vibhishek Kashyap. 2013. Image Steganography usingDCT, DST,Haar and Walsh Transform. International Journal of Computer Applications, Vol. 65, No.17, Hal. 34-37.
[5] Khalid Sayood, Introduction to Data Compression, Academic Press, 2000.
[6] Linawati dan Henry P. Panggabean. 2004, Perbandingan Kinerja Algoritma Kompresi Huffman, Lzw,dan Dmc pada Berbagai Tipe File. Integral, Vol. 9, No. 1, 2004, hal 14-15
[7] Nosrati, Masoud., RonakKarimidan Mehdi Hariri.2011. An Introduction to Steganography Methods.World Applied Programming, Vol 1, No 3, 191-195, Agustus 2011
[8] Safaat, Nazruddin.2012. Pemrograman Aplikasi Mobile Smartphone dan Tablet PC Berbasis Android.Bandung : Informatika
[9] Singh, Dr. Ajit dan Meenakshi Gahlawat. 2013. Secure Data Transmission using Watermarking andImage Compression. International Journal of Advanced Research in Computer Engineering &Technology, Vol. 2, No.5, Hal. 1709-1715.
[10] Saleh Saraireh. 2013. A Secure Data Communication System Using Cryptography andSteganography. International Journal of Computer Networks & Communications (IJCNC) Vol. 5 No.3, May 2013.
APPENDIX



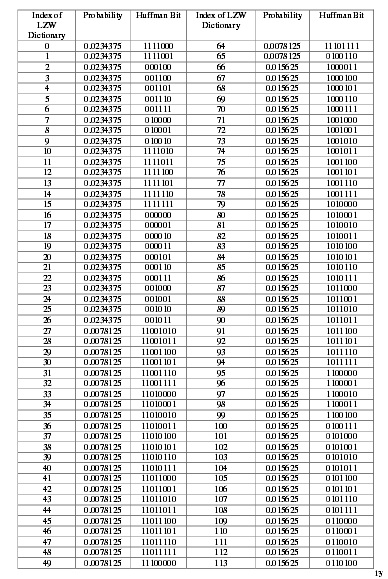
 Table 2 Huffman Tree
Table 2 Huffman Tree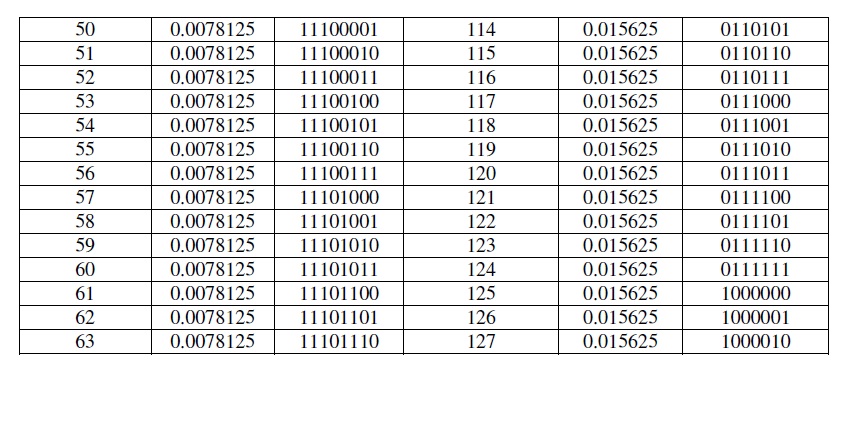
 Table 3 Samples of input message
Table 3 Samples of input message
 Table 4 LZW compression process
Table 4 LZW compression process
 Table 5 Compression Ratio of input message with
different in the sum of character and symbol 0
Table 5 Compression Ratio of input message with
different in the sum of character and symbol 0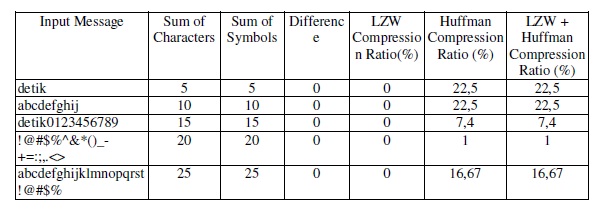
 Table6 Compression Ratio of input message
with the sum of characters of three and different sum ofsymbols
Table6 Compression Ratio of input message
with the sum of characters of three and different sum ofsymbols
 Tabel 7 Input Message
Tabel 7 Input Message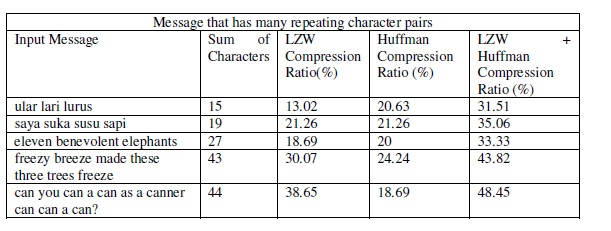
 Table8 Processing Time
Table8 Processing Time