
7415cnc08.pdf
PERFORMANCE IMPROVEMENT BY TEMPORARY EXTENSION OF AN HPC CLUSTER
Pil Seong Park
Department of Computer Science, University of Suwon, Hwasung, Korea
ABSTRACT
Small HPC clusters are widely used in many small labs since they are easy to build and cost-effective. When more power is needed, instead of adding costly new nodes to old clusters, we may try to make use of the idle times of some servers in the same building, that work independently for their own purposes, especially during the night. However such extension across a firewall raises not only some security problem but also a load balancing problem caused by heterogeneity of the resulting system. In this paper, we devise a method to solve such problems using only old techniques applicable to our old cluster systems as is, without requiring any upgrade for hardware or software. We also discuss about how to deal with heterogeneity and load balancing in application, using a two-queue overflow queuing network problem as a sample problem
KEYWORDS
HPC clusters, Security, NFS, SSH tunnelling, Load balancing
1. INTRODUCTION
A variety of architectures and configurations have appeared according to the desire of getting more computing power and higher reliability by orchestrating a number of low cost commercial off-the-shelf processors. One such example is a computer cluster, which consists of a set of loosely or tightly coupled computers that are usually connected to each other through a fast LAN and work together so that they can be viewed as a single system in many respects.
Many kinds of commercial clusters are already on the market. However the technologies to build similar systems using off-the-shelf components are widely known (e.g., see [1]), and it is easy to build a low-cost small cluster [2]. Many small labs commonly build their own cluster, and gradually grow it by adding more dedicated nodes later. However, instead of adding dedicated nodes, if there are some nodes that are being used for other purposes on the same LAN, we may try to utilize their idle times as long as they are not always busy enough, especially during the night. The Berkeley NOW (Network of Workstations) project is one of such early attempts to utilize the power of clustered machines on a building-wide scale [3]. However such extension gives rise to difficulties in security, administering the cluster, and load balancing for optimal performance.
In this paper, we consider some technical issues arising in extending a small Linux cluster to include some non-dedicated nodes in the same building across a firewall. Of course there are already various new good methods that can be used to avoid such technical issues. However we do not adopt such state-of-the-art technologies, since the sole purpose of this paper is to achieve our goal with our old HPC cluster as is, without any hardware or software upgrade. Some results of the experiments to evaluate the performance of the extended system are given at the end.
2. BACKGROUND
2.1. HPC Clusters
Computer clusters may be configured for different purposes. Load-balancing (LB) clusters are configurations in which nodes share computational workload like a web server cluster. Highperformance computing (HPC) clusters are used for computation-intensive purposes, rather than handling IO-oriented operations. High-availability (HA) clusters improve the availability of the cluster, by having redundant nodes, which are then used to provide service when system components fail. The activities of all compute nodes are orchestrated by a cluster middleware that allows treating the whole cluster system via a single system image concept.
Well-known HPC middlewares based on message passing are the Message Passing Interface (MPI) [4] and the Parallel Virtual Machine (PVM) [5], the former being the de facto standard. Many commercial or non-commercial implementation libraries have been developed in accordance with the MPI standard. LAM/MPI, FT-MPI, and LA-MPI are some of widely used non-commercial libraries, and their technologies and resources have been combined into the ongoing Open MPI project [6].
An HPC cluster normally consists of the dedicated nodes that reside on a secure isolated private network behind a firewall. Users normally access the master/login node (master, for short) only, which sits in front of compute nodes (slave nodes, or slaves for short). All the nodes in an HPC cluster share not only executable codes but also data via insecure NFS (Network File System). It is perfectly all right as long as the whole cluster nodes are on a secure LAN behind a firewall. However, to extend the cluster to include other nodes outside of the firewall, we will be confronted with many problems with security and data sharing among nodes. Moreover, such growth results in a heterogeneous cluster with nodes of different power, possibly running different Linux versions.
2.2. Linux/Unix File Sharing Protocols
NFS, created by Sun Microsystems in 1984, is a protocol to allow file sharing between Linux/UNIX systems residing on a LAN. Linux NFS clients support three versions of the NFS protocol: NFSv2 (1989), NFSv3 (1995), and NFSv4 (2000). However the NFS protocol as is has many problems in extending the cluster, since its packets are not encrypted and due to other shortcomings to be discussed later.
Other alternatives to NFS include AFS (Andrew File System), DFS (Distributed File System), RFS (Remote File System), Netware, etc. [7]. There are also various clustered file systems shared by multiple servers [8]. However we do not adopt such new technologies since they are not supported by our old cluster’s hardware and software.
3. TEMPORARY EXTENSION OF AN HPC CLUSTER ACROSS A FIREWALL
We would like to extend our old cluster (consisting of the master and slave nodes in Figure 1) to include some other nodes, say Ext1 and Ext2, outside of a firewall, as shown in Figure 1. The master node generally has attached storage that is also accessible by diskless slave nodes using insecure NFS. Since NFS relies on the inherently insecure unencrypted UDP protocol (up to NFSv3), transactions between host and client are not encrypted, and IP spoofing is possible. Moreover, firewall configuration is difficult because of the way NFS daemons work.
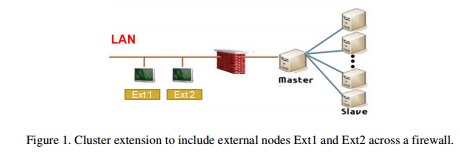
3.1. NFS over TCP and Fixing NFS Ports SSH tunnelling, which is based on SSH port forwarding, is commonly used to encrypt some unencrypted packets or to bypass firewalls, e.g., see [9,11]. SSH tunnels support only TCP protocols of fixed ports, but NFS uses UDP protocols by default, and the ports of some daemons essential for the operation of NFS are variable.
Fortunately NFS over TCP protocols are also supported from the Linux kernel 2.4 and later on the NFS client side, and from the kernel 2.4.19 on the server side [12]. Since all the nodes of our old cluster satisfy this condition, we can make NFS work over TCP just by specifying the option “-o tcp” in the mounting command. The following shows an example of mounting the NFS server’s /nfs_dir directory on the client’s mount_pt.
# mount -t nfs -o tcp server:/nfs_dir mount_pt
For tunnelling, we need fix NFS ports. The daemons essential for NFS operation are 2 kinds. Portmapper (port 111) and rpc.nfsd (port 2049) use fixed ports, while rpc.statd, rpc.lockd, rpc.mountd, and rpc.rquotad use ports that are randomly assigned by the operating system. However the ports of the latter can be fixed by specifying port numbers in appropriate configuration files [13], as shown below.
The ports of the first three (i.e., rpc.statd, rpc.lockd, and rpc.mountd) can be fixed by adding the following lines in the NFS configuration file /etc/sysconfig/nfs, for example,
STATD_PORT=4001
LOCKD_TCPPORT=4002
LOCKD_UDPPORT=4002
MOUNTD_PORT=4003
The rest ports can be fixed by defining a new port number 4004 in the configuration file /etc/services, for example
rquotad 4004/tcp
rquotad 4004/udp
3.2. Setting up an SSH
Tunnel For tunnelling of NFS, it is necessary for the server to mount its own NFS directory to be exported to clients. Hence on the server side, the configuration file /etc/exports has to be modified, for example, for exporting its /nfs_dir to itself,
/nfs_dir localhost (sync,rw,insecure,root_squash)
where “insecure” means it allows connection from ports higher than 1023, and “root_squash” means it squashes the root permissions for the client and denies root access to access/create files on the NFS server for security.
Now an SSH tunnel has to be set up from the client’s side. On the client side, to forward the ports 11000 and 12000, for example, to the fixed ports 2049 (rpc.nfsd) and 4003 (rpc.mountd), respectively, we can use the command
# ssh nfssvr -L 11000:localhost:2049 -L 12000:localhost:4003 -f sleep 600m
where “nfssvr” is the IP or the name of the NFS server registered in the configuration file /etc/hosts, and “-f sleep 600m” means that port forwarding is to last for 600 minutes in the background.

When connected to the NFS server, an SSH tunnel will be open if the correct password is entered. Then the NFS server’s export directory can be mounted on the client’s side. The following command is an example to mount the /nfs_dir directory of the NFS server on the /client_dir directory of the client
# mount -t nfs -o tcp,hard,intr,port=11000, mountport=12000 localhost:/client_dir
3.3. Suggested Structure
Even though the NFS through an SSH tunnel is encrypted, it has a serious drawback if we cannot completely trust the local users on the NFS server [14]. For example, if some local user on the NFS server can login on the server and create an SSH tunnel, any ordinary user on the server can mount the file systems with the same rights as root on the client.
One possible solution might be prohibiting local users’ direct login to the NFS server to prevent creating an SSH tunnel. One simple way is changing all local users’ login shells from /bin/bash to /sbin/nologin in the file /etc/passwd. However it causes another problem. In general, the master node normally works as the NFS server too in small HPC clusters. However local users should be allowed to login the master node to use the cluster, which is dangerous when using NFS through an SSH tunnel, as was pointed out previously.
Figure 3 is an alternative of the structure of an extended HPC cluster that takes everything into account. The structure has a separate NFS server which does not allow local users’ login. An SSH tunnel can be created by the root user on Ext1 or Ext2, and local users just login on the master node to use the cluster.
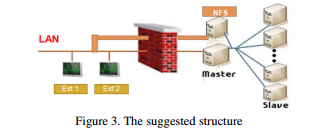
The firewall setting of the master node does not need any modification. However, since the NFS service is provided through SSH tunnelling, it is required for the NFS server to open the port 22 only to the computation nodes outside of its firewall.
The NFS server should be configured so that it releases as little information about itself as possible. For example, services like portmapper should be protected from outside. And it is suggested to specify explicitly the hosts that are allowed to access all the services on the NFS server. This can be done by setting ALL:ALL in the configuration file /etc/hosts.deny, and listing only the hosts (or their IPs) together with the services which are allowed to access, in the file /etc/hosts.allow.
The use of “rsh” command, which is not encrypted, is common on old HPC clusters with old middlewares. Fortunately LAM/MPI v.7.1.2 allows SSH login with an authentication key but without a password, e.g., see [15].
4. DYNAMIC LOAD BALANCING
The original HPC cluster may be homogeneous, i.e., the power of all nodes may be the same. However, the extended cluster may be heterogeneous or may behave like heterogeneous one even if all the nodes have the same power, since the communication speeds between nodes are not the same depending on various factors: the types of network, existence of firewall, and encryption. Moreover the workload of the non-dedicated nodes outside of the firewall may change continually, and the communication speed may change continually because of the traffic on the outside LAN. Hence we need to use a dynamic run-time load balancing strategy [16], while initially assigning equal amount of work to the original slave nodes of the cluster.
Data partitioning and load balancing have been important components in parallel computation. Since earlier works (e.g., see [17]), many authors have studied load balancing using different strategies on dedicated/non-dedicated heterogeneous systems [18,19,20,21], but it was not possible to find related works on the security problems arising in cluster expansion, which is more technical rather than academic.
4.1. The Sample Problem
Dynamic load balancing strategies depend on the problem we deal with, and we need introduce our problem first. We would like to solve the old famous two-queue overflow queuing problem given by the Kolmogorov balance equation.
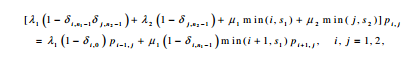
where δi,j is the Kronecker delta, pi,j is the steady-state probability distribution giving the probability that there are ij customers in the j-th queue. It is assumed that, in the i-th queue, there are si parallel servers and ni-si-1 waiting spaces. Customers enter the i-th queue with mean arrival rate λi, and depart at the mean rate µi. The model allows overflow from the first queue to the second queue if the first queue is full. The total number of possible states is n1×n2.
It is known that no analytic solution exists, and the balance equation has to be solved explicitly. We can write the discrete equation as a singular linear system Ax = 0 , where x is the vector consisting of all states pi,j’s. Even for systems with relatively small numbers of queues, waiting spaces, and servers per queue, the size of the resulting matrix is huge. The numbers of waiting spaces in our problem are 200 and 100 in each queue, respectively, and the resulting matrix size is 20,000ⅹ20,000.

