
A New Interconnection Topology For Network On Chip
Laxminath Tripathy and Chitta Ranjan Tripathy
Veer Surendra Sai University of Technology, Burla, India
Abstract
The architecture of networks on chip (NOC) highly affects the overall performance of the system on chip (SOC). A new topology for chip interconnection called Torus connected Rings is proposed. Due to the presence of multiple disjoint paths between any source and destination pair, this topology exhibits high fault tolerance capability. The proposed routing method can tolerate faults adaptively. TCR is simple in design and highly scalable. The detailed design and topological parameters are compared with alternate topologies.
Keywords
Torus, Ring, MCR, Static routing algorithm, Dynamic fault-tolerant routing.
1.Introduction
The Network-on-Chip (NoC) is an interconnection of cores and sub-systems of a System on Chip (SOC). The performance of SOC highly depended upon the efficiency of the underlying topology of the NOC. In [34], different NoC configurations are investigated and it has been shown that no single NoC can be found to provide optimal performance across a range of applications. Over the past ten years, there has been a substantial amount of research on different aspects of NoC [30], including architecture, circuits, and systems that employ NOC, but many of these works have used conventionally, electrical signaling for communication. As the number of cores is increasing to meet the high-performance requirement of the Multiprocessor System-on-Chip (SoC), the Network-on-Chip (NoC) offered a scalable and alternative method for communication in place of a bus-based system which had the limitation of the bandwidth and more power consuming [29]. The topology decides the physical architecture of the interconnection network and it plays a vital role in faster communication in parallel systems. The fault tolerant routing plays an equal role in faster communication.
2.Related Work
There are many interconnection topologies have been suggested, such as Mesh, Star, Mstar, Torus, Chordal Ring Folded Torus, Fat-tree, hierarchical Ring, DL (2m), Rgrid, X Mesh etc [1-6], torus embedded hypercube [8], meshes of torus [9] , and concentrated form of topology CMesh [31], DMesh [32], ONoC [18-20], CTorus, and other topology which uses concentration [25-28]. 2D Mesh [21-24], Torus[7-8], and Dia Torus[35] are used for designing of the network on chip. The degree of some of the topologies discussed in this literature is not uniform. The degree of both mesh and torus topologies are 4 and the mesh connected ring (MCR) [1] is 3. The mesh connected ring interconnect topology is shown in Fig.1.


Figure1. Mesh Connected Ring (MCR)
From Fig.1 it can be observed that the degree of MCR is not uniform as nodes present at the boundary positions have degree 2 and rest nodes have degree 3.A system is highly scalable without modifying the individual nodes if it has a constant node degree. Similarly, the hardware cost per node of a system is less if it has a small node degree[7]. These two desirable properties are present in the proposed topology.
3.The Proposed Topology
The proposed topology is illustrated in Fig.2 and it has a uniform node degree of 3. The routing algorithm elaborated in [1] cannot choose an alternate path if a fault occurs during routing so it is called static routing as it is fixed. The fault tolerant routing for the selection of an alternate path in case of fault situation is not discussed. As in our proposed topology, there exist many alternate paths between any source and destination pair so we proposed a dynamic routing (fault-tolerant routing) technique which can select an alternate path in presence of the fault. As the node degree is uniform so, it is easier to design router. The router complexity mainly depends upon the network node connectivity (number of input and output ports) [13-17], so router complexity of TCR is less than both torus and MCR. Due to the presence of multiple disjoint paths, it enhances fault tolerance property. This topology is highly scalable and it can be achieved by increasing the number of nodes in both X and Y direction without changing the degree of the nodes.


Figure 2. Torus Connected Ring(TCR) Interconnection Topology
A.Topology of the TCR
Any set of interconnected processors can be represented as a simple undirected graph in which each vertex represents a unique processor and each edge represents a connection path/link between two processors if path exists.
Definition 1 A n-dimensional torus topology can be represented as an interconnected structure that has A0×A1×A2×···An-1 nodes where n represent dimension. Each node of the torus can be represented by an n coordinate vector(a0,a1,a2…an-1) where 0≤ai≤Ai-1.Two nodes (a0,a1,a2… an-1) and (b0,b1,b2…bn-1 ) are connected if and only if there exists an i such that ai=(bi±1) mod n and ai=bj for all i.
Definition 2 Ring topology can be represented by an undirected simple graph G (V, E) with the following properties : i) V – { x | 0≤x≤n-1, n, x Є I }; ii)E – { < x1, x2> | |x1-x2| -1 (mod n)}.
Definition 3 Torus-Connected Rings (TCR) topology can be represented by a simple connected graph G (V, E) with the following properties –i){ (x, y , z) | 0≤x≤n-1, 0≤y≤m-1, 0≤z≤3, n, m, x, y, z ЄI }; ii) There exist edge between two nodes node1(x1,y1,z1) and node2 (x2,y2,z2) in following cases
Case 1: |x1-x2|=1, |y1-y2|=0, z1 ⊕ z2 =2
Case 2: |x1-x2|=0, |y1-y2| =1, z1 ⊕ z2 =2
Case 3: |x1-x2|=0, |y1-y2|=0, z1 ⊕ z2=1 or 3
Case 4: |x1-x2|=0, |y1-y2|=m-1, z1 ⊕ z2=2
Case 5: |y1-y2|=0, |x1-x2|=n-1, z1 ⊕ z2=2
TCR can be scalable in two levels. The first layer is ring topology which has four connected nodes. This ring can be treated as a super-node, which can improve the overall performance of the system by enhancing local characteristics of the system. The torus can be called as the next level of the network where super nodes are connected. TCR of 64 nodes is depicted in Fig.2 which consists of 4×4 connected super-nodes. The coordinates of any node in the topology can be represented by three positions. For example node A (x, y, z) represents the position of the torus in x and in y-direction and third coordinate z represents the position number within a ring which has ranged from 0 to 3. In other words, the first coordinate depicts a position along X axis;the second coordinate depicts a position along the Y axis and the third one is the node number within the ring which starts from left to right. For example node (2, 2, 0) indicate 0th node of the ring of super-node present at the position (2, 2).
Example-1 Let us consider two nodes of TCR for n=3 are node1 (0,3,0) and node2 (3,3,2). Check whether an edge exists, in between two nodes. |x1-x2|=3, |y1-y2|=0, z⊕ z2=2. So, according to case 5 of the definition, there exists an edge between two nodes.


Figure 3. Illustration of multiple disjoint paths (black shaded)between node 000 to 333.
B.Routing in TCR
The routing of the message in TCR can be both static and/or dynamic. Dynamic routing can be used in case of faults and in case of a fault-free situation, static routing can be used. In the static routing, a path is established and all packets follow the same path which is fixed. But in case of fault occurrence, the route will be chosen dynamically.
C.Static routing
The routing in TCR is an improvement over x-y routing. The route selection depends upon the difference between the source position number and destination position number.
Let the position of two nodes are the source (x1,y1) and destination (x2,y2) So, this difference must satisfy any one of the following condition of the algorithm and the route can be chosen accordingly.
If (|x1-x2|= n-1 & |y1-y2|! = m-1)
then select a chain link in x direction and |y1-y2| number of torus links in y direction.
else if (|x1-x2|! = n-1 & |y1-y2| = m-1) then select a chain link in y direction and |x1-x2| number of torus links in x direction.
else if (|x1-x2| = n-1 and |y1-y2| = m-1) then select chain link in x and subsequently choose chain link in y direction.
else if (|x1-x2| ! = n-1 and |y1-y2| != m-1) then select |x1-x2| number of torus links in x direction and subsequently |y1-y2| number of torus links in y direction.
else If (|x1-x2|= |y1-y2| =0) then select |z1-z2| number of links in same rings.
else no route exists.
D.Dynamic Routing
Faults can be at any level of the topology. It may be at the node level or link level. Further, the link fault can present at any link of torus or ring. As there exist more than one path between any source and destination. So, when a fault occurs, an alternate path can be chosen adaptively without restarting the network. Following conventions are used to indicate the different links and illustrated in Fig 4.
ChainX=chained link in the x-direction
ChainY=chained link in the y-direction
LinkX=link in x-direction of a torus
LinkY= link in y-direction of a torus
The fault can be present location and it must satisfy any one case depending upon the postion of a faulty node or link. The alternate path can be selected according
Case 1: If path= ChainX ChainY/ChainYChainX and fault is at Chain X then path=ChainY ChainX/ChainY linkX…(n- 1)times
If fault is at chainY path= ChainXLinkY LinkY…(m-1) times/ ChainX ChainY
Case 2: If path= ChainX LinkY LinkY…k times /ChainYLinkXLinkX….(k times)and if the fault is at ChainX/chainY
Path= LinkY LinkY…k (times). ChainX/ LinkXLinkX….(k times) ChainY
Case 3: If Path= (Lanky Lanky…k ChainX) / ( LinkX LinkX….(k times) ChainY) and if fault is at ChainX/ChainY
Path= (Lanky … (k times)LinkX…(n-1) (times ) / (LinkX ….(k times) (Lanky … (m-1 times))
Case 4: If fault is at any linkY/linkX path then linkY/LinkX can be replaced by
(LinkXlinkYChainX)/(LinkYLinkXLinkY)
4. Description Of Routing Algorithm
The path of the message is computed from the difference between positions of both source and destination. This position difference between source and destination gives the number of hops/links in between them. So, accordingly, the chained link, LinkX or LankY are selected. The static routing chooses the shortest path from the source to the destination. The dynamic routing selects the alternate path to the destination in case of link or node fault.
From the static routing algorithm, it is observed that there are five cases depending upon which route to the destination is selected. The five cases of the static routing algorithm are followings:
Case 1: (|x1-x2|= n-1 and |y1-y2|! = m-1), choose a chain link in x direction and then |y1-
y2| number of torus links in y-direction.
Case 2: (|x1-x2|! = n-1 and |y1-y2| = m-1), choose a chain link in y-direction and
subsequently |x1-x2| number of torus links in x-direction.
Case 3: (|x1-x2| = n-1 and |y1-y2| = m-1), choose chain link in x and subsequently choose chain link in y-direction.
Case 4: (|x1-x2| ! = n-1 and |y1-y2| != m-1), choose |x1-x2| number of torus links in x-
direction and subsequently |y1-y2| number of torus links in y-direction.
Case 5: (|x1-x2|= |y1-y2| =0), choose |z1-z2| number of links in same rings.
In order to ensure deadlock-free routing, the router performs computation such that packet position should be: i) if (x2-x1)<0, then the destination node is left side of current node by |x2-x1| number of links, select left link (LinkX) or ring structure upper half of the links of torus as the output channels; ii) if x1=x2 and y2-y1 < 0, then the destination node is |y2-y1| LinkY below the current node, choose the below link(LinkY) of same column or the right half of the links in the ring structure of the torus as the output channels; iii) if x1=x2 and y2>y1, then the destination node is above current node by y2-y1 links in y-direction, choose the above link (LinkY) of same column or the left half of the links in the ring structure of the torus as the output channels; iv) if x1=x2 and y1=y2, the position of both source and destination nodes are in the same ring. If two nodes are adjoining in the same ring, then forward packets to the destination node directly, otherwise, if z1 is either 1 or 3, then forward packets in a counter-clockwise, and if z1 is 0 or 2, then forward packets in a clockwise direction.


Figure 4. Illustration of multiple faults (dashed links) and alternate paths (bold links).
5.The Properties Of Proposed Topology
The node degree of TCR is 3 irrespective of dimension. TCR topology has following important good topological properties (Assume the number of nodes =4n2) as follows:
Property 1 TCR topology is a regular and the node degree is 3. Due to the uniformity in degree, the design of router complexity is less. The hardware cost per node of a topology is directly related to node degree and a constant node degree indicates that the system is scalable without modifying the individual nodes [6].
Property 2 The total number of links present in TCR topology is 6n2. The number of links that connect each ring is 2n2, each ring has 4 links. So, the total of n2 ring and the total number of links is 4n2+2n2=6n2.
Property 3 TCR topology is highly scalable. The scalability is defined as the property of expanding the network size, getting constant performance. The scalability of TCR can be achieved by adding the same number of nodes in both x and y-direction. For example, l number of rings can be added in both x and y-direction of an m×m TCR topology and the new structure will be extended (m+l) × (m+l) TCR topology. After adding new nodes to the connection patterns and links remain the same.
Property 4 The network diameter is defined as the maximum of all the shortest paths between any two nodes. For example, a ring of 4 nodes has diameter 2 and the diameter of the torus is n. The diameter of TCR can be computed from addition of diameter of the torus and the product of the diameters of both torus and ring. Hence, the diameter of TCR is (n+2×n) =3n. The torus is a network with constant node degree and is highly scalable architecture, and it has a smaller network diameter in comparison to mesh.
Property 5 The bisection width of a network is the minimum number of links whose removal disconnect the graph and cuts it in two equal halves. The bisection width of TCR is 2n.
Property 6 The average distance of a TCR network topology structure is the sum of average distances of both torus and ring. The average distance of each ring is 4/4=1 and the n×n torus structure is n/2. So the average distance of TCR is (n/2+n/2×1) =n. As the average distance of MCR is 4n/3 so, latency is more than TCR.
Property 7 The cost of a network is the scalar product of the degree and diameter. As degree and diameter of TCR is 3 and 3n respectively, so the cost is 9n.
Property 8 The packing density of a network is defined as the total number of nodes per total network cost. It indicates the size of chip area of VLSI layout. The larger package density indicates the smaller chip area of VLSI design layout which is also a desirable property. As the size of TCR is N and cost =9n so packing density is N/9n where N=4n2
6. Comparison Studies
The performance analysis of TCR topology structure is based upon comparisons of topological properties such as node diameter, average distance, bisection width, and packing density. The diameter of a network affects node latency. The average latency of a network is proportional to the average distance[10]. The bisection width is directly proportional to the throughput. The throughput or a given network topological structure is maximum for the efficient routing algorithm and ideal flow control mechanism [7]. So, the desirable property of any topology is that the network average distance should be minimized as it affects latency in communication, the diameter should more be less and bisection width should be more. The packing density is expressed in terms of the total number of nodes present in a topology per unit cost. The packing density is related to the size of the VLSI chip layout. The higher packing density is the smaller size of the chip design layout.
The excellent features of TCR over MCR and Octagon for Ubiquitous Computing (OUC) [33] are shown in table-1. In our discussion, the number of nodes is N = 4n2.
TABLE 1 Performance matrices of Mesh, TCR, MCR, and OUC.

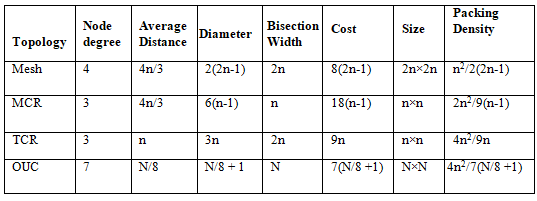
TABLE 2 The detail numerical comparisons


From table 1 and 2, it is observed that the diameter, average distance of TCR is less than MCR and OUC and bisection width of TCR is more than MCR but less than OUC. As more number of links are present in OUC and the degree of the router is 7 so, the cost and complexity of router is more. As the bisection width of OUC is more, so the network will be less congestion than other topologies under consideration. The cost of OUC is highest amongst all topologies under consideration. The network diameter has a direct impact on communication overhead [7]. The communication latency is less for small diameter of a topology. The diameter analysis is illustrated in Fig.5. For small size network, the diameter of OUC is small among all topologies
under consideration, but if the node size increases the diameter of OUC, MCR and Mesh increases faster than TCR.


Figure 5. Network Diameter analysis

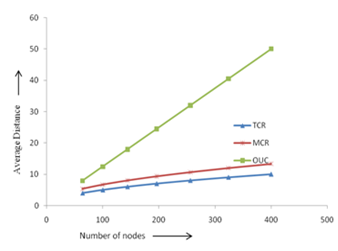
Figure 6. Network Average distance analysis


Figure 7. Network Bisection width analysis


Figure 8. Cost analysis


Figure 9. Packing Density analysis
This proposed new topology structure called Torus-Connected Ring is regular, flat, and highly scalable, and it exhibits high fault tolerance capability. In a fault-free situation, this TCR interconnect network uses a static routing and dynamic routing is used in a faulty situation. After comparison of topological parameters of TCR with other alternate topologies, it is found that TCR has good topological properties. Due to the presence of multiple disjoint paths between any source and destination, it has better fault tolerance capability than mesh, torus, MCR, and OUC. The cost of TCR is less than both MCR and OUC. TCR topology has a better trade-off between network cost and performance. As the packing density of TCR is highest among MCR, Mesh, and OUC so, it will be suitable for chip design. It is simple in design and efficient interconnection topology for NOC.
Acknowledgment
The authors would like to thank anonymous reviewers and editor.
References
[1] LIU Youyao and HAN Jungang, “Mesh-Connected Rings Topology for Network-on-Chip,” The journal of china universities of post and telecommunications, vol.20, no.5, 2013 30-36.
[2] Wang wei, Qiao Lin, Tang Zhi-zhong. “Survey on the Networks-on-Chip Interconnection Topologies,” Computer Science, vol.38, no.10, 2011, pp.1-5.
[3] Erno Salminen, Ari Kulmala, Timo D. H¨am¨al¨ainen. “Survey of Network-on-chip,” Proposals. Http://www.ocpip.org/socket/whitepapers.
[4] WANG Wei,QIAO Lin,YANG Guang-Wen, et al. “A Kind of Hierarchical Ring Interconnection Networks-on-Chip,” Chinese Journal of Computer, vol.33, no.2, 2010, pp.326-334.
[5] Liu Youyao, Han Jungang, Du Huimin., “DL(2m): A New Scalable Interconnection Network for System-on-Chip,” Journal of computers, vol.4, no.3, 2009, pp.201-207.
[6] ZHU Xiao-jing. “A Recursive Scalable Topology for Network on Chip,” Chinese Journal of Computer, vol.34, no.5, 2011, pp.924-930.
[7] Duato, J., Yalamanchili, S., Ni, L. “Interconnection Networks: an Engineering Approach,” Publishing House of Electronics Industry, Beijing 2004.
[8] N. Gopalakrishna Kini M. Sathish Kumar Mruthyunjaya H.S.”A Torus Embedded Hypercube Scalable Interconnection Network for Parallel Architecture,” IEEE International Advance Computing Conference (IACC) 2009, pp.6-7.
[9] J .F. Fang, J.Y. Hsiao and C.Y. Tang, “Embedding Meshes and TORUS Networks onto degree-four chordal rings,” IEEE Proc. Comput. Digit. Tech., vol. 145, no. 2,1998.
[10] Pablo Fuentes, Enrique Vallejo, Carmen Mart´ınez, Marina Garc´ıa, Ram´on Beivide, “comparison study of scalable and cost effective interconnection networks for HPC,”. In: 411st International Conference on Parallel Processing Workshops (ICPPW), 2012, pp.594-595.
[11] A. R. Ashok Kumar S. V. Rao, Diganta Goswami, “NS3 Simulator for a study of Data Center Networks,” IEEE 12th International Symposium on Parallel and Distributed Computing, 2013, pp.224-231.
[12] Xin Yuana, Santosh Mahapatra, Michael Lang b, Scott Pakin, “Static load-balanced routing for slimmed fat-trees,” Journal of Parallel Distributed Computing, vol.74, 2014, pp.2423–2432.
[13] Salminen E, Kulmala A, Hamalainen T D. “On network-on-chip comparison,” Proceedings of the 10th Euro micro Conference on Digital System Design: architectures, methods and tools (DSD’07), 2007, pp.503−510.
[14] Abdul Quaiyum Ansaria, Mohammad Rashid Ansaria, Mohammad Ayoub Khan, “Modified quadrant-based routing algorithm for 3D Torus Network-on-Chip architecture,” Perspectives in Science vol. 8, 2014, pp.718—721.
[15] Ebrahimi, M., Daneshtalab, M., Liljeberg, P., Plosila, J., Flich, J., Tenhunen, H., “Path-based partitioning methods for 3D networks-on-chip with minimal adaptive routing,” IEEE Transaction on Computer. vol.63, no.3, 2014, pp. 718—733.
[16] Khan, M.A., Ansari, A.Q., “Quadrant-based XYZ dimension order routing algorithm for 3-D asymmetric torus routing chip,” In: Proc. International Conference on Emerging Trends in Networks and Computer Communications (ETNCC 2011), India, 2011, pp. 121—124.
[17] Khan, M.A., Ansari, A.Q., “An efficient tree-based topology for Network-on-Chip,” In: Proc. World Congress on Information and Communication Technology (WICT 2012), Mumbai, 2012, pp. 1316—1321.
[18] P. Ho, G. Shen, S. Subramaniam, H. T. Mouftah, C. Qiao, and L. Wosinska, “Guest editorial energy-efficiency in optical networks,” IEEE Journal on Selected Areas in Communications, vol. 32, no. 8, 2014, pp.1246-1260.
[19] A. Shacham, K. Bergman, and L.P. Carloni, “Photonic Networks-on-Chip for Future Generations of Chip Multiprocessors,” IEEE Trans. Computers, vol.57, no.9, 2008, pp.1246-1260.
[20] Ian O’Connor, “Optical solutions for system-level interconnect,” SLIP’04, 2004, pp. 79-88.
[21] Z. Chen, H. Gu, Y. Yang, L. bai, H. Li, “A Power Efficient and Compact Optical Interconnect for Network-on-Chip,” IEEE Computer Society, vol. 13, no. 1, 2013, pp. 5-8.
[22] K. Sankaralingam and et. al. “Distributed micro architectural protocols in the trips prototype processor,” In IEEE/ACM International Symposium on Microarchitecture (MICRO), 2006, pp. 480–491.
[23] M. B. Taylor, W. Lee, S. Amarashinghe, and A. Agarwal. “Scalar operand networks: On-chip interconnects for ilp in partitioned architectures,” In International Symposium on High-Performance Computer Architecture (HPCA), pp. 341–353, 2003.
[24] S. R. Vangal, J. Howard, G. Ruhl, S. Dighe, H. Wilson, J. Tschanz, D. Finan, A. Singh, T. Jacob, S. Jain, V. Erraguntla, C. Roberts, Y. Hoskote, N. Borkar, and S. Borkar. “An 80-tile sub-100-w teraflops processor in 65-nm cmos,” vol. 43, no.1, 2008.
[25] R. Das, S. Eachempati, A. Mishra, V. Narayanan, and C. Das. “Design and evaluation of a hierarchical on-chip interconnect for next-generation cmps,” In International Symposium on High-Performance Computer Architecture (HPCA), 2009, pp. 175–186.
[26] B. Grot, J. Hestness, S. W. Keckler, and O. Mutlu, “Express cube topology for on-chip interconnects,” In International Symposium on High-Performance Computer Architecture (HPCA), Raleigh, NC 2009, pp.163–174.
[27] J. Kim, J. Balfour, and W. J. Dally. Flattened butterfly topology for on-chip networks. In IEEE/ACM International Symposium on Micro architecture (MICRO), Chicago, Illinois, Dec. 2007.
[28] Y. Pan, P. Kumar, J. Kim, G. Memik, Y. Zhang, and A. Choudhary, “Firefly: Illuminating future network-on-chip with nanophotonics,” In proceedings International Symposium on Computer Architecture (ISCA), Austin, TX, 2009.
[29] Dally, W.J., Towles, B., “Principles and Practices of Interconnection Networks,” Morgan Kaufmann, San Francisco, CA, 2004.
[30] N. D. E. Jerger and L.-S. Peh, “On-Chip Networks”, ser. Synthesis Lectures on computer Architecture. San Rafael, CA: Morgan Claypool, 2009.
[31] J. Balfour and W. J. Dally, “Design tradeoffs for tiled CMP on-chip networks,” in Proc. Int. Conf. Supercomput. (ICS), Carns, Queensland, Australia, 2006, pp.187–198.
[32] Z. Chen, H. Gu, Y. Yang, L. bai, H. Li, “A Power Efficient and Compact Optical Interconnect for Network-on-Chip,” IEEE Computer Society, vol. 13, no. 1, 2013, pp. 5-8.
[33] Zheng Wang, Huaxi Gu, Yawen Chen, Yintang Yang, Kun Wang, “3D network-on-chip design for embedded ubiquitous computing systems,” Journal of Systems Architecture, 2016, pp. 1–8.. http: //dx.doi.org/10.1016/ j.sysarc.2016.10.002.
[34] M. Kim, J. Davis, M. Oskin, T. Austin, “Polymorphic on-chip networks,” in: Proceedings of ISCA, 2008, pp.101–112.
[35] Deewakar Thakyal and Pushpita Chatterjee, “DIA-TORUS:A novel topology for Network On Chip design,” International Journal of Computer Networks & Communications (IJCNC) Vol.8, No.3, May 2016, pp.137-148.
Authors

Er Laxminath Tripathy received BE.(Computer Science & Engg) from Biju Patnaik University of Technology, Rourkela, Odisha in 2003 and MTech from IIIT, Bhubaneswar in year 2009. Presently he is continuing Ph.D. (Computer Science & Engg) in VSSUT, Burla, Odisha. His research interest is in interconnection network, parallel computing and fault tolerant routing.

Prof. (Dr.) C.R. Tripathy received the B.Sc. (Engg.) in Electrical Engineering from Sambalpur University and M.Tech. in Instrumentation Engineering from I.I.T., Kharagpur respectively. He got his Ph.D. in the field of Computer Science and Engineering from I.I.T., Kharagpur, India. He has more than 200 numbers of publications in different national and international Journals and Conferences. His research interest includes Dependability, Reliability and Fault–tolerance of Parallel and Distributed system. He is recipient of “Sir Thomas Ward Gold Medal” for research in Parallel Processing. He is a fellow of Institution of Engineers, India. He has been listed as leading scientist of World 2010 by International Biographical Centre, Cambridge, England, Great Britain.

